
Benchmarking OpenAI's Whisper
“Whisper” is an amazing new open-sourced program that performs Automated Speech Recognition (ASR), producing text transcriptions from raw audio data files. Developed by OpenAI, it represents a monumental leap forward in terms of accuracy and robustness. The algorithm that powers the Whisper model uses a deep-learning architecture known as an encoder-decoder Transformer. These Transformer models execute a high number of matrix math operations, which makes them perform very slowly on general purpose computers – but they are well suited to run GPUs.
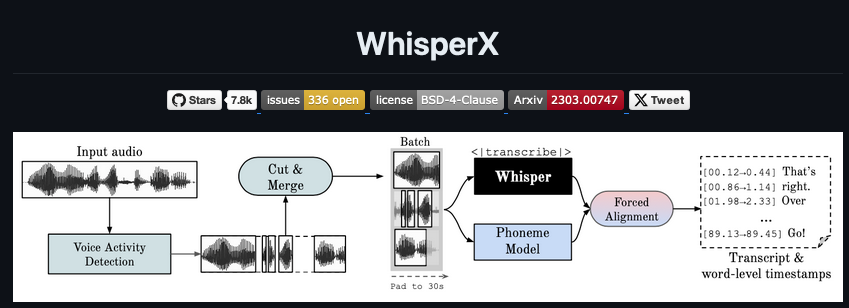
We were extremely happy with how well Whisper performed on Earnings Call audio files. Not only were the results much more accurate than our previous transcription algorithms, but Whisper also provided capitalization and punctuation out of the box. Using Whisper was a no-brainer, but before we proceeded to implementation we needed to answer many questions. Since there are many different types of GPUs on the market, we wanted to know which GPU model would be well suited to run thousands of transcription jobs. Some questions we had were:
- Should we run in the Cloud or buy our own hardware?
- If we run in the Cloud, there are many different types of hardware to choose from, which one has the best price-to-performance characteristics?
- If we build our own hardware, what should we buy? Should we buy used or new equipment?

Here is a great article benchmarking 18 different consumer GPUs on the market. This was a great starting point, but it didn’t have any commercial grade GPUs on the list. Then, we found this GitHub discussion on the same topic which included some commercial grade GPUs such as the NVIDIA V100 among others.
The other issue was that both of these benchmarks used the Official version of Whisper, which doesn’t include some tuning parameters such as batched inference to speedup the transcription job. To make Whisper faster, we decided to utilize WhisperX, which yields speed boosts up to 70x faster than real-time on the large-v2 model, and it includes Speaker Diarization out of the box.
Naturally, we had to run our own tests on some hardware. In order to run the large-v3 model in WhisperX, we had to pick GPUs with at least 10GB of VRAM
For Cloud hardware, we picked two separate hosts:
- g4dn.xlarge, which has a NVIDIA Tesla T4 GPU ($0.526/hour)
- g5.xlarge, which has a NVIDIA A10G GPU ($1.006/hour)
For our custom hardware setup, we purchased the NVIDIA RTX 3080 GPU. This GPU can be purchased on eBAY as used for roughly $600.


For our test, we used an audio file with duration of 45 minutes and can be found here.
Benchmark Results
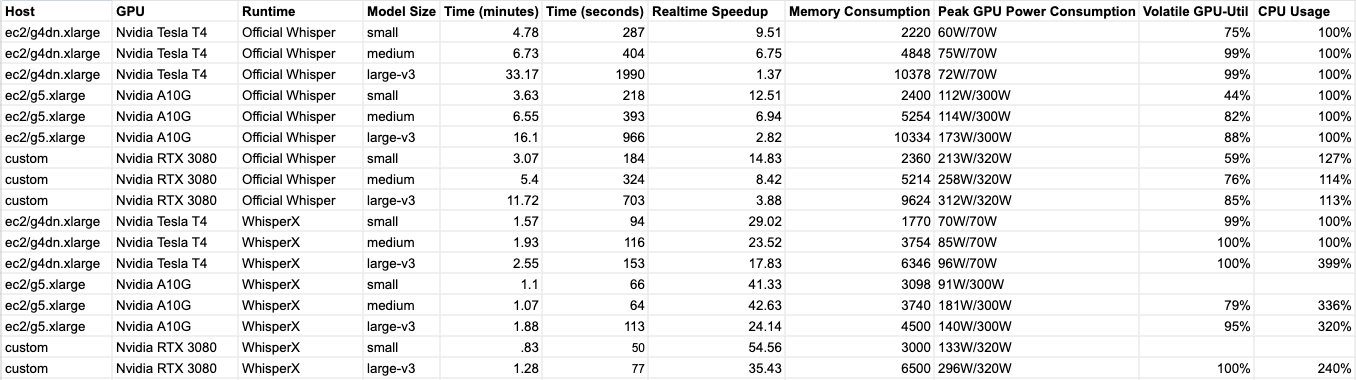
Overall, WhisperX runs a lot faster than the Official version of Whisper. On all fronts, the RTX 3080 performed better than the A10G and the T4. For the WhisperX large-v3 model, the 3080 finished the transcription job in roughly 68% of the time it took the A10G, and 50% of the time it took the T4 to complete.
Appendix: Launching and Running WhisperX in Ec2
Just in case this is useful to anyone, here are the steps we took to get WhisperX up and running on Ec2 Hardware.
First thing is to launch your instance. You need to navigate to the AWS Ec2 console and click on launch on instance.
We used Ubuntu 20 without any drivers preinstalled (Note we had a problem with Ubuntu 22, which gave us some missing library error). We will manually install NVIDIA drivers in a next steps.

Select instance type:
Select your SSH key (or create it).
Ensure you have enough disk space to install packages. 50GB should be enough:
Install Nvidia Drivers
sudo apt update
sudo apt -y upgrade
sudo apt install -y ubuntu-drivers-common ffmpeg
sudo ubuntu-drivers autoinstall
sudo rebootInstall conda
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
~/miniconda3/bin/conda init bash- logout/login
Install WhisperX
conda create --name whisperx python=3.10
conda activate whisperx
conda install pytorch==2.0.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
pip install git+https://github.com/m-bain/whisperx.gitRunning WhisperX
wget https://earningscall.biz/f/7fa81ef0-68ad-4b43-8bb3-36dee84d5d35.mp3
# First time whisper models need to be downloaded, so it will be slow.
time whisperx --model large-v3 7fa81ef0-68ad-4b43-8bb3-36dee84d5d35.mp3
# Run it again with models now downloaded in local filesystem
time whisperx --model large-v3 7fa81ef0-68ad-4b43-8bb3-36dee84d5d35.mp3Installing Official Whisper
pip install -U openai-whisperRunning Official Whisper
time whisper --model medium 7fa81ef0-68ad-4b43-8bb3-36dee84d5d35.mp3