
Building Financial Intelligence Tools with Earnings Call Data — A Developer's Handbook
Introduction
The fintech developer landscape has changed significantly over the past three years. Where building a sophisticated financial research tool once required institutional-grade data contracts, expensive Bloomberg terminals, and months of data pipeline engineering, the modern financial data API developer has access to high-quality, structured financial data through simple REST integrations that go live in hours.
Earnings call data sits at the center of this shift. The transcripts, audio files, speaker-segmented text, and metadata from quarterly earnings calls represent some of the richest qualitative financial intelligence available. For engineers and fintech builders who know how to work with this data programmatically, it opens up an entire category of financial intelligence tools that were previously out of reach for small teams.
This handbook is a practical guide for developers. It covers what earnings call data is, why it matters, how to access it through an API, and how to build the most common types of financial intelligence tools on top of it. Whether you are building your first earnings call API tutorial project or architecting a production-grade data pipeline for an institutional client, this guide will help you move faster and build better.
What Are Financial Intelligence Tools and Why Developers Build Them
Before diving into the technical implementation, it is worth establishing what financial intelligence tools actually are and why they represent such a compelling development opportunity for fintech builders.
Financial intelligence tools are applications that transform raw financial data into actionable insight. They span a wide range: portfolio research dashboards that surface key metrics alongside company commentary, alert systems that notify users when specific language appears in an earnings call, AI-powered question-answering tools that let analysts query a company's entire earnings history in natural language, and quantitative signal generators that feed automated trading strategies. What these tools share is that they take structured financial data as input and produce insight as output.
Earnings call data is uniquely valuable as the foundation for these tools for reasons that go beyond what most developers initially expect. Unlike financial statements, which are backward-looking summaries of what already happened, earnings call transcripts contain forward-looking guidance, unscripted management commentary, and live analyst questioning that reveals information not available anywhere else. A CFO who says "we expect margin expansion in the second half" is making a commitment that carries real investment signal. A CEO who repeatedly avoids a direct question about inventory levels is communicating something meaningful through that avoidance. As researchers at the National Bureau of Economic Research have documented, the linguistic content of earnings calls carries statistically significant predictive power for subsequent stock price movements.
For developers, this creates a clear opportunity. The data is high-signal, it is generated quarterly by thousands of companies, and it is increasingly accessible through purpose-built APIs. The teams that build the best tools on top of this data, fastest, are the ones that win.
A practical example is Earnings Call News, which aggregates earnings call transcripts, summaries, and related financial intelligence into a developer-friendly resource. It illustrates how structured earnings call data can serve as the foundation for building research platforms, AI applications, market monitoring tools, and other next-generation fintech products.
The Earnings Call Data Landscape: What You Are Working With
A successful financial data API developer starts with a clear picture of what the data actually contains before writing a single line of code. Earnings call data typically comes in several layers, each with different use cases and analytical properties.
The full transcript text is the most commonly used layer. This is the complete word-for-word record of everything said on the call, from the IR representative's opening legal disclaimer through to the final analyst question. High-quality providers segment this into prepared remarks (the structured presentation by management) and the Q&A section (the live question and answer exchange), which have fundamentally different analytical properties. Prepared remarks are scripted and legally reviewed. Q&A is unscripted and often more revealing.
Speaker data adds another critical layer of value. Knowing not just what was said, but who said it and in what role, is essential for any tool that performs speaker-level analysis. When a sell-side analyst from a major institution asks a pointed question about gross margin and the CFO gives a two-sentence answer before moving on, the identity and role of both parties carries as much analytical weight as the words themselves.
Raw audio files enable a different class of applications entirely. Voice tone analysis, speech pattern detection, and media player interfaces all require audio access alongside the transcript. Slide decks, where available, add the visual context that accompanied the verbal presentation and are particularly useful for tools that combine document understanding with spoken content. Call metadata rounds out the picture: the company ticker, exchange, fiscal year and quarter, conference date and time, and transcript availability status.
Your First Earnings Call API Tutorial: Getting Started in Minutes
The fastest way to understand what an earnings call API delivers in practice is to make your first call. This earnings call API tutorial walks through the core steps using the EarningsCall API, which offers both Python and JavaScript SDKs alongside a standard REST interface with no sales call or procurement process required.
Start by installing the Python SDK:
pip install --upgrade earningscall
Then set your API key and fetch your first transcript:
import earningscall
from earningscall import get_company
earningscall.api_key = "YOUR-SECRET-API-KEY-GOES-HERE"
company = get_company("aapl") # Lookup Apple, Inc by its ticker symbol
transcript = company.get_transcript(year=2026, quarter=1)
print(f"{company} Q1 2026 Transcript Text: \"{transcript.text[:100]}...\"")
To access speaker-level data with names and titles, set level=2:
from earningscall import get_company
company = get_company("aapl")
transcript = company.get_transcript(year=2026, quarter=1, level=2)
speaker = transcript.speakers[1]
print(f"Name: {speaker.speaker_info.name}")
print(f"Title: {speaker.speaker_info.title}")
print(f"Text: {speaker.text}")
To retrieve prepared remarks and Q&A as separate fields, use level=4:
transcript = company.get_transcript(year=2026, quarter=1, level=4)
print(f"Prepared Remarks: \"{transcript.prepared_remarks[:100]}...\"")
print(f"Q&A: \"{transcript.questions_and_answers[:100]}...\"")
The JavaScript SDK follows the same pattern with zero external dependencies:
import { getCompany, setApiKey } from "earningscall";
setApiKey("YOUR-SECRET-API-KEY");
const company = await getCompany({ symbol: "AAPL" });
console.log(`Getting transcripts for: ${company}`);
For the earnings calendar, which returns all calls scheduled for a given date:
from datetime import date
from earningscall import get_calendar
calendar = get_calendar(date(2026, 5, 1))
for event in calendar:
print(f"{event.company_name} - Q{event.quarter} {event.year} "
f"Transcript Ready: {event.transcript_ready}")
Output:
Tilray Brands, Inc. - Q2 2026 Transcript Ready: True
Delta Air Lines, Inc. - Q4 2025 Transcript Ready: True
Constellation Brands, Inc. - Q3 2025 Transcript Ready: True
The time from installation to first successful API response is typically under ten minutes. By default, the library grants access to Apple Inc. and Microsoft for testing. To unlock 9,000+ companies, set your API key from EarningsCall API pricing. The EarningsCall developer guide has the full endpoint reference and SDK documentation.
How a Financial Data API Developer Structures an Earnings Call Pipeline
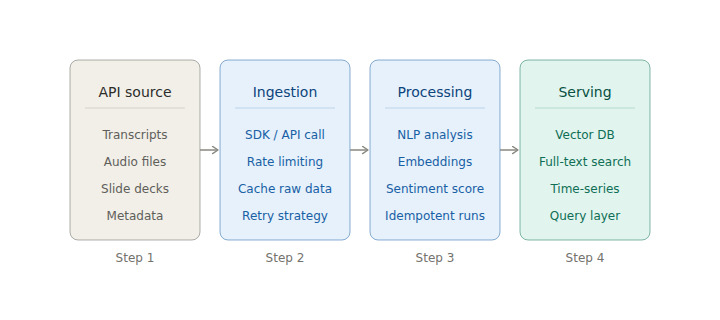
Moving from a single API call to a production-grade data pipeline requires deliberate architectural thinking. A well-structured financial data API developer workflow separates three distinct concerns: data ingestion, data processing, and data serving.
Data ingestion is the layer that communicates with the API. Its responsibilities are to pull data reliably, handle rate limits gracefully, manage retries on transient failures, and persist raw API responses before any transformation occurs. For earnings call data specifically, ingestion runs in two modes: scheduled pulls that backfill or refresh historical data for a defined universe of companies, and event-driven pulls that trigger when a new call is detected via the calendar endpoint. A robust ingestion layer treats the raw API response as the source of truth and stores it before any downstream transformation. This single discipline saves enormous pain later.
The SDK makes iterating across all historical transcripts for a company straightforward:
from earningscall import get_company
company = get_company("aapl")
for event in company.events():
transcript = company.get_transcript(event=event)
if transcript:
print(f"Q{event.quarter} {event.year}: \"{transcript.text[:80]}...\"")
else:
print(f"Q{event.quarter} {event.year}: No transcript found.")
To iterate across the full S&P 500 universe:
from earningscall import get_sp500_companies
for company in get_sp500_companies():
print(f"{company.company_info} -- {company.company_info.sector}")
Data processing transforms raw transcript text into the structures your specific application needs. For a research tool this might mean chunking transcripts into sections, tagging speaker turns, and indexing text for search. For an AI pipeline it means generating vector embeddings for semantic retrieval or feeding text through a language model for summarization and extraction. For a signal generation tool it means running NLP classifiers and persisting sentiment scores alongside the raw text as a time series. The key architectural principle here is that processing should be idempotent and re-runnable so that evolving your pipeline logic never requires re-ingesting raw data from the API.
Data serving is the layer your application queries at runtime. Depending on your query patterns this might be a relational database with full-text search extensions, a vector store for semantic retrieval, a time-series database for signal history, or a combination of all three. The right serving layer is determined by your use case, not by what is currently popular. If users search for keywords across transcript history, full-text search is the right tool. If they ask natural language questions, a vector store with an LLM is more appropriate. If they query signal histories across large time windows, a column-oriented time-series store wins.
For teams evaluating which provider best fits this architecture, the complete guide to earnings call APIs covers the key technical and commercial differences between providers in detail.
Building AI-Powered Financial Intelligence Tools with Earnings Call Data
The single biggest shift in financial intelligence tools development over the past two years has been the integration of large language models. For a financial data API developer, earnings call transcripts are among the best possible inputs for LLM-powered applications because they are long-form, information-dense, and consistently structured across thousands of companies and quarters.
The most widely used architectural pattern is retrieval-augmented generation, commonly called RAG. In this pattern, transcript text is chunked into segments, embedded using a model such as OpenAI's text-embedding-3-small or a locally hosted alternative, and stored in a vector database. When a user asks a question, the system retrieves the most semantically relevant chunks and passes them to a language model to generate a grounded, cited answer. The result is an application that can respond to queries like "what did Apple's CFO say about services margins in the last three quarters?" or "which semiconductor companies mentioned inventory headwinds in Q1 2026?" with high accuracy, grounded in the actual transcript text rather than in model memory.
Speaker segmentation is particularly valuable in this context. Because the EarningsCall API separates prepared remarks from Q&A and maps each speaking turn to a named speaker and role, RAG pipelines built on this data are aware of who said what. A query like "what did management say about capital allocation guidance?" can retrieve the precise CFO statement rather than an analyst question that happened to mention the same topic. This speaker-awareness is a meaningful differentiator for professional research applications.
Beyond RAG, earnings call data is well suited to fine-tuning and few-shot prompting for domain-specific tasks including earnings summary generation, forward guidance extraction, and management tone classification. The Journal of Finance has published peer-reviewed research demonstrating that NLP-derived signals from earnings calls carry statistically significant return predictability, which gives quantitative teams a strong academic foundation to build on.
Common Use Cases for Earnings Call API Tutorial Projects
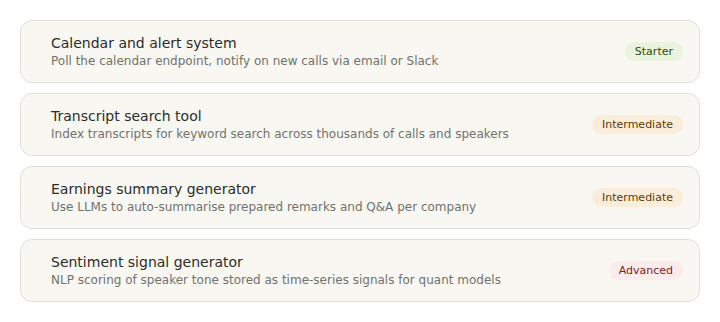
Understanding the most common use cases helps developers scope their first earnings call API tutorial project realistically and choose the right architecture from the start. The following categories represent the most frequently built types of financial intelligence tools using earnings call data, ordered by implementation complexity.
An earnings calendar and alert system is the simplest and most focused starting point. The application polls the calendar endpoint on a schedule, identifies upcoming calls for a watchlist of companies, and sends notifications via email, Slack webhook, or push notification when calls are scheduled or transcripts become available. This is a self-contained project that can be built and deployed in a weekend and serves as a solid foundation for more sophisticated features.
A transcript search and research tool adds a layer of complexity by indexing transcript content for full-text search and building a query interface on top. Users can search for keywords across thousands of calls, filter by company, speaker, date range, or section type, and retrieve relevant passages with full speaker context. PostgreSQL with tsvector full-text indexing or a dedicated search engine such as Elasticsearch are the most common backing stores for this use case.
An earnings summary and highlight generator uses a language model to automatically produce structured summaries of each earnings call, extracting key metrics, guidance statements, and notable management commentary. The prepared remarks versus Q&A segmentation from the API makes it straightforward to generate separate summaries for each section with different prompting strategies. This use case is particularly valuable for research teams covering large company universes who cannot manually review every transcript.
A sentiment signal generator computes quantitative sentiment scores from transcript text using NLP classifiers or LLM-based scoring, stores scores as a time series, and makes them queryable as inputs to broader investment models. Researchers at Seeking Alpha and institutional NLP teams have consistently found that well-constructed earnings call sentiment signals provide meaningful information when combined with traditional fundamental factors. For developers choosing a provider for signal generation workloads, a comparison of the best earnings call APIs for developers covers latency, coverage, and SDK support in detail.
Financial Data API Developer Best Practices for Production Systems
Building production-grade financial intelligence tools requires more than getting the API call right. Several practices consistently separate maintainable, reliable fintech applications from fragile prototypes.
Rate limiting and backoff handling are essential from the first day in production. Even well-maintained APIs return 429 responses under load, and a production pipeline should implement exponential backoff with jitter rather than retrying a failed endpoint immediately. Wrapping your API client in a retry decorator costs very little engineering time and prevents an entire class of production failures.
Caching raw API responses before any processing step avoids redundant API calls and provides a reliable re-processing path when pipeline logic evolves. Storing the raw JSON response in a simple object store alongside a timestamp and request parameters costs almost nothing in storage and saves significant engineering time when debugging downstream issues or backfilling historical data for new features.
Monitoring data freshness is underappreciated in financial data pipelines. A pipeline that silently falls behind because a scheduled job failed or an upstream response format changed can cause significant problems before anyone notices. Simple freshness checks that alert when expected data has not arrived within a defined window catch most of these failures before they affect downstream users.
Testing your integration before promoting to production is straightforward with the EarningsCall API. Running your full pipeline against a controlled dataset validates the integration end-to-end before any production traffic flows through it. Teams looking for deeper guidance on selecting and evaluating API providers can also refer to which earnings call API is best for fintech products for a structured evaluation framework.
Frequently Asked Questions
Q: What programming languages work best for an earnings call API tutorial project? The EarningsCall API is language-agnostic since it uses a standard REST interface returning JSON, making it accessible from any language. Official SDKs are available in Python and JavaScript, which are the lowest-friction starting points. Python dominates data pipeline and ML workloads while JavaScript is the natural choice for full-stack web applications.
Q: How do I handle rate limiting in the EarningsCall SDK? The SDK has a built-in retry strategy that handles rate limiting and HTTP 5xx errors automatically. By default it retries with exponential backoff at 3, 6, 12, 24, and 48 second intervals. You can customise this behaviour:
import earningscall
earningscall.retry_strategy = {
"strategy": "exponential",
"base_delay": 1,
"max_attempts": 10,
}
Q: What is the difference between prepared remarks and Q&A in the API response? Prepared remarks are the scripted section where management presents their financial results. Q&A is the unscripted live exchange with analysts. For AI and NLP applications these sections have different properties and should be processed and stored separately. Prepared remarks are suitable for summary generation; Q&A is more valuable for tone analysis and signal generation.
Q: How accurate are earnings call transcripts returned by the API? Leading providers report accuracy rates above 95%, with domain-specific language models trained on financial vocabulary improving recognition for technical financial terminology. For production applications that depend on transcript accuracy, validating a sample against source audio is a recommended quality check before launch.
Q: Can earnings call data be used in a commercial product? This depends entirely on the terms of service of your data provider. Always review licensing terms before using earnings call data in a commercial application. Most providers offer tiered commercial licenses based on usage volume and application type.
Q: How should a financial data API developer approach real-time versus historical data? Historical ingestion is typically a one-time or scheduled batch job that backfills a defined date range and company universe. Real-time ingestion requires an event-driven architecture that monitors the calendar endpoint and triggers processing immediately when a new transcript becomes available. These two modes have different reliability profiles and should be implemented as separate pipeline components with separate monitoring.
Conclusion
The combination of high-quality earnings call data and accessible financial data APIs has made it genuinely possible for small teams of engineers and fintech builders to construct financial intelligence tools that would have required institutional infrastructure just a few years ago. The technical barrier has come down dramatically. The remaining differentiator is how deeply developers understand the data they are working with and how deliberately they architect the systems they build on top of it.
An earnings call API tutorial project remains one of the highest-signal ways to develop that understanding quickly. The data is rich and consistently structured, the use cases are well defined, and the path from first API call to a working prototype is measured in hours rather than weeks. For any financial data API developer building in this space, starting with a focused, well-scoped project and iterating from real usage is the most reliable path to a production-grade tool that creates genuine value.
The earnings call data space will continue to grow as AI capabilities make it possible to extract more signal from the same underlying text. Developers who build deep familiarity with this data today will be well positioned to take advantage of those capabilities as they mature.
For full API documentation and SDK setup guides, visit the EarningsCall developer guide. For regulatory filings and supplementary financial data, the SEC EDGAR database is the authoritative public source.