How to Build a Hedge Fund Earnings Sentiment Dashboard with EarningsCall API
Quarterly earnings calls are among the most information-dense events in public markets. In under an hour, a company's management team transmits signals about growth trajectory, cost pressure, competitive positioning, and strategic confidence. For a hedge fund analyst covering dozens of holdings, that density creates as much of a bottleneck as an opportunity.
Listening to calls live, taking notes, and reading transcripts manually is accurate but slow. By the time an analyst team has reviewed transcripts across a full portfolio, the early-mover window has often closed. A dedicated earnings sentiment dashboard powered by a hedge fund earnings call API solves that problem by surfacing language signals automatically, letting analysts focus their attention where the data flags meaningful deviation.
This guide walks through exactly how to build one, from data sourcing to signal design, using real code and a production-ready architecture.
Why Earnings Call Sentiment Matters for Hedge Funds
Earnings call transcripts carry two types of information: numerical and linguistic. The numerical data, revenue, margins, guidance, appears in press releases and SEC filings. The linguistic data is harder to access and easier to misread. Management tone, hedging language, word choice under analyst questioning, and the gap between prepared remarks and off-script answers are all signals that quantitative models have historically underweighted.
A growing body of research supports this view. Studies published through the National Bureau of Economic Research have documented that textual signals from earnings communications carry information beyond the numerical content of the same calls. Investopedia's guide to earnings calls similarly notes that tone and language shift measurably when management is under pressure or uncertain about forward guidance.
For any team evaluating a hedge fund earnings call API, the value proposition is direct: structured transcript data enables systematic language analysis that was previously available only through expensive data vendors or entirely manual review.
What an Earnings Sentiment Dashboard Should Deliver
Before writing any code, define the outputs your earnings sentiment dashboard needs to produce. Three outputs cover most hedge fund use cases.
The first is a per-call sentiment score for every portfolio holding, updated within minutes of a transcript becoming available. The second is a trend view showing how a company's language has shifted across four to eight quarters, with flagged deviations from its own historical baseline. The third is a cycle view ranking the most positive and most negative calls in a given earnings period, allowing analysts to prioritise their review queue rather than working through every call sequentially.
These three outputs shape every downstream technical decision. The pipeline needs to be fast, reliable, and capable of handling the volume of calls that arrive in concentrated reporting windows, particularly the two weeks after quarter-end when the majority of large-cap companies report.
Choosing a Hedge Fund Earnings Call API
Data sourcing is where many internal tools stall. Building a scraper for earnings transcripts is technically possible but expensive to maintain. Provider reliability, transcript timing, and coverage breadth all vary significantly across data vendors.
EarningsCall is a practical foundation for this kind of system for three reasons. Coverage extends to 9,000+ public companies, which matters for funds with positions outside the large-cap universe. The Python SDK reduces integration time from days to hours. And the structured transcript format, with prepared remarks and Q&A separated at the level 4 access tier, aligns precisely with what an NLP sentiment model needs.
As covered in Building Financial Intelligence Tools with Earnings Call Data, the API separates transcript content into distinct sections. That separation is critical for any team that wants to treat management-scripted language differently from analyst-questioned responses.
Building the Hedge Fund Earnings Call API Pipeline
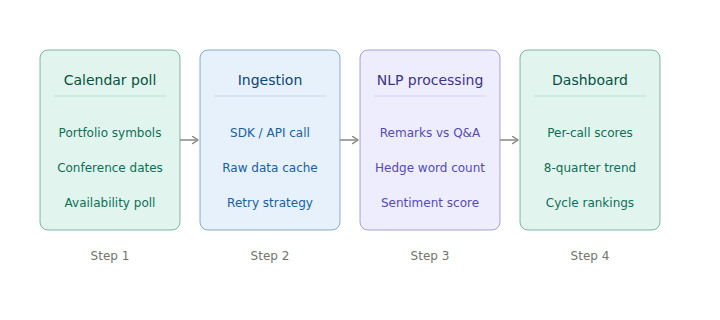
The pipeline runs in four stages: calendar polling, transcript ingestion, NLP processing, and dashboard output. Building each stage as an independent, deployable unit allows the NLP layer to be iterated without rebuilding the data layer.
Stage one: calendar polling. Schedule a lightweight job to run each morning during earnings season. It should check the EarningsCall calendar for any portfolio holdings with a conference date within 24 hours, then queue them for transcript fetch once the call ends.
import earningscall
from earningscall import get_calendar
from datetime import date
earningscall.api_key = "YOUR-API-KEY"
calendar = get_calendar(date(2026, 5, 1))
Stage two: transcript ingestion. Once a company's transcript_ready field confirms availability, fetch the full transcript at level 4. This returns prepared remarks and questions and answers as distinct objects, which is the structural foundation the NLP model depends on.
from earningscall import get_company
company = get_company("aapl")
transcript = company.get_transcript(year=2026, quarter=1)
At level 4, the transcript object includes a full speaker breakdown alongside the prepared remarks and Q&A split. Prepared remarks reflect scripted management communication. Q&A reflects real-time responses under analyst pressure. The divergence between the two in tone, hedge word frequency, and forward-looking language density is where the most durable signals tend to live.
Stage three: NLP processing. The NLP layer ingests the raw transcript text and produces a set of sub-scores: overall sentiment polarity, hedge word frequency ratio, forward-looking language density, and a confidence index derived from declarative versus qualified statement proportions. Open-source libraries handle the base classification, but a custom dictionary for financial-domain hedging terms is worth building. Standard NLP libraries miss domain-specific hedges like "subject to macro conditions," "we remain cautious," and "consistent with our prior guidance."
Stage four: dashboard output. Scores are written to a time-series store and surfaced in an internal dashboard. A single company view shows current-quarter scores alongside the eight-quarter history. A cycle view ranks all portfolio holdings for the current reporting period.
Signal Design: What the Earnings Sentiment Dashboard Should Measure
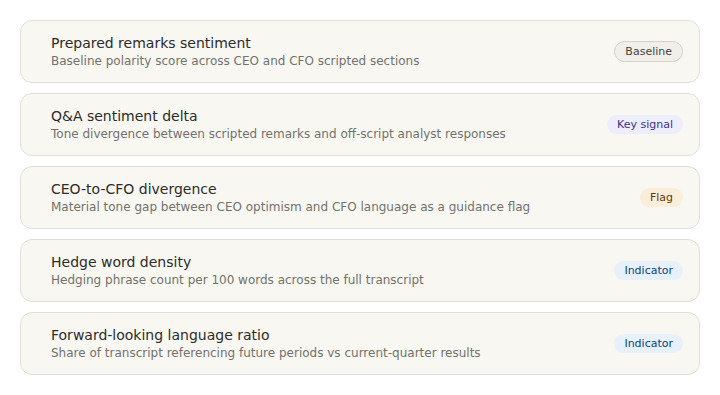
The most consequential design decision in any earnings sentiment dashboard is what to measure and what to ignore. Five signals cover the most meaningful linguistic dimensions of an earnings call.
The first is prepared remarks sentiment: a baseline polarity score across the CEO and CFO scripted sections. The second is Q&A sentiment delta, the difference in tone between scripted remarks and off-script responses. A meaningful negative delta, where management speaks positively in prepared remarks but becomes more guarded under analyst questioning, is among the most informative divergences to track.
The third signal is CEO-to-CFO divergence. When the CEO's language is materially more optimistic than the CFO's, that gap is worth flagging as a potential indicator of guidance risk. The fourth is hedge word density: the proportion of hedging phrases per hundred words of transcript. The fifth is forward-looking language ratio, measuring how much of the transcript references future periods versus current-quarter results.
As Seeking Alpha's coverage of earnings analysis has noted, management language often shifts before numerical guidance revisions become explicit. A well-designed dashboard surfaces those shifts systematically rather than relying on analyst intuition alone.
Architecture Decisions That Matter in Production
Three architecture choices make the largest difference once the system moves from prototype to live use.
The first is treating transcript fetch and NLP processing as independent steps connected by a job queue. When the API returns a transcript, the raw data should be immediately written to a cache layer. The NLP job reads from the cache, not from the live API. This means the NLP layer can be rerun, retrained, or updated without re-fetching transcript data.
The second is building the retry and rate-limiting logic at the ingestion layer using the SDK's built-in retry configuration, which supports exponential backoff. During peak reporting weeks, when fifty or more transcripts may arrive in a 48-hour window, robust retry logic prevents silent queue failures.
The third is maintaining a per-company baseline. Raw sentiment scores are less useful than relative scores. A company that consistently uses cautious language will score low in absolute terms but may be showing unusual optimism relative to its own history. Storing rolling eight-quarter baselines and surfacing z-scores rather than raw numbers makes the signal significantly more actionable.
For a broader view of how investment teams use transcript data beyond sentiment, How Investors Use Earnings Call Data for Smarter Decisions covers the full range of analytical approaches in use today.
FAQ
Can a hedge fund access earnings call transcripts programmatically?
Yes. The EarningsCall API provides structured transcript access for 9,000+ public companies via a Python SDK and REST interface. Transcripts are available at multiple access levels, including separated prepared remarks and Q&A sections that enable section-specific analysis.
What is the difference between prepared remarks and Q&A in an earnings call?
Prepared remarks are scripted statements delivered by management at the start of the call, covering financial results, operational highlights, and forward guidance. Q&A is the unscripted exchange between management and analysts that follows. Research consistently shows that language in the Q&A section differs from prepared remarks, particularly when management faces pointed questions on specific topics.
What NLP signals are most studied in hedge fund earnings analysis?
Academic research published through the Journal of Finance and affiliated working papers has examined a range of textual signals from earnings communications. Hedge word density, sentiment divergence between scripted and unscripted sections, and forward-looking language ratio have all received attention in the quantitative finance literature as potential inputs to systematic trading models.
How quickly are earnings call transcripts available through the API?
Transcript availability varies by company and call. The EarningsCall calendar endpoint includes a transcript_ready field that allows pipelines to poll for availability without unnecessary retries or hard-coded delays.
What programming languages does EarningsCall support?
EarningsCall provides a Python SDK and a JavaScript SDK with TypeScript support, both covering transcript retrieval, calendar access, and company lookup.
Conclusion
Building an earnings sentiment dashboard on a hedge fund earnings call API is a production engineering problem as much as a research one. It requires clean data sourcing, deliberate signal design, and infrastructure that holds up under the concentrated data volume of earnings season.
The approach outlined here solves one problem at a time: structured data access first, NLP processing second, signal calibration third. The EarningsCall API handles the data sourcing layer, leaving the team's proprietary effort for the signal design and scoring models where the analytical edge actually lives.
For full API documentation and integration guides, visit the EarningsCall developer guide. For company filings and supplemental financial data, SEC EDGAR is the primary public resource.