
Using Earnings Call Transcripts to Reduce Portfolio Risk: A Quant Approach
Quantitative risk models are built almost entirely on numerical inputs: price volatility, factor exposures, correlation matrices, and historical drawdowns. These models are precise, but they share a blind spot. They cannot see risk building inside a company before it shows up in price action. By the time volatility spikes, the underlying signal that caused it may have been visible weeks earlier, buried in how management spoke about their own business.
Earnings transcript risk analysis offers a way to close that gap. Earnings call transcripts contain language signals such as hedging frequency, tone shifts, and management confidence that often precede the numerical deterioration a traditional risk model eventually picks up. This guide walks through how quant teams can build a transcript-based risk signal using quant earnings data from the EarningsCall API, and how to integrate that signal into an existing portfolio risk framework.
Why Numerical Risk Models Miss Early Warning Signs
Traditional risk models are reactive by design. Volatility-based measures, value-at-risk calculations, and factor models all rely on historical price behavior. They are excellent at quantifying risk that has already materialized, but structurally limited in detecting risk that is still forming.
Earnings calls happen at a specific moment: after the quarter has closed but before the next quarter's results are known. Management has visibility into trends that have not yet appeared in reported numbers. The way they discuss those trends, confidently or cautiously, directly or evasively, carries information that a pure numbers-based model cannot access.
Academic research has examined this gap directly. Studies published through the National Bureau of Economic Research have found that the textual content of corporate disclosures, including earnings communications, contains information not fully reflected in contemporaneous stock prices or analyst estimates. This is the foundation for treating earnings transcript risk analysis as a complement to, not a replacement for, traditional quantitative risk methods.
What Earnings Transcript Risk Analysis Actually Measures
Before building a pipeline, it helps to define the specific linguistic signals that correlate with rising company risk. Four categories cover most of what a transcript-based risk model should track.
The first is hedging language frequency. Phrases like "subject to macro conditions," "depending on execution," and "we remain cautious" increase when management is less certain about forward performance. A rising hedge word count across consecutive quarters, even with flat or modestly positive numerical results, can signal building uncertainty.
The second is guidance language consistency. Comparing how management frames forward guidance quarter over quarter reveals whether confidence is increasing, holding steady, or eroding. A shift from specific numerical guidance to vaguer directional language is a pattern worth flagging.
The third is Q&A evasiveness. When analysts press on a specific topic and management responses become longer, more qualified, or redirect to unrelated points, that pattern is measurable and has been associated in academic literature with underlying operational stress.
The fourth is CEO-CFO divergence. A gap between the CEO's tone and the CFO's tone on the same call, where one is notably more optimistic than the other, can indicate internal disagreement about the company's outlook that has not yet been resolved into a unified public message.
Sourcing Quant Earnings Data from EarningsCall API
Building a systematic risk signal requires structured, programmatic access to transcript data across a full coverage universe. EarningsCall provides this through a Python SDK covering 9,000+ public companies, with transcripts available at multiple access levels.
import earningscall
from earningscall import get_company
earningscall.api_key = "YOUR-API-KEY"
company = get_company("aapl")
transcript = company.get_transcript(year=2026, quarter=1)
At level 4 access, the transcript object separates prepared remarks from the Q&A section and includes speaker identification. This separation is essential for quant earnings data pipelines, since prepared remarks reflect scripted, reviewed language while Q&A reflects spontaneous, unscripted response. Treating the two sections separately produces a materially cleaner signal than processing the full transcript as one undifferentiated block.
As detailed in Building Financial Intelligence Tools with Earnings Call Data, this section-level structure is the same foundation used across sentiment and intelligence pipelines built on the EarningsCall API.
Building the Risk Signal Pipeline
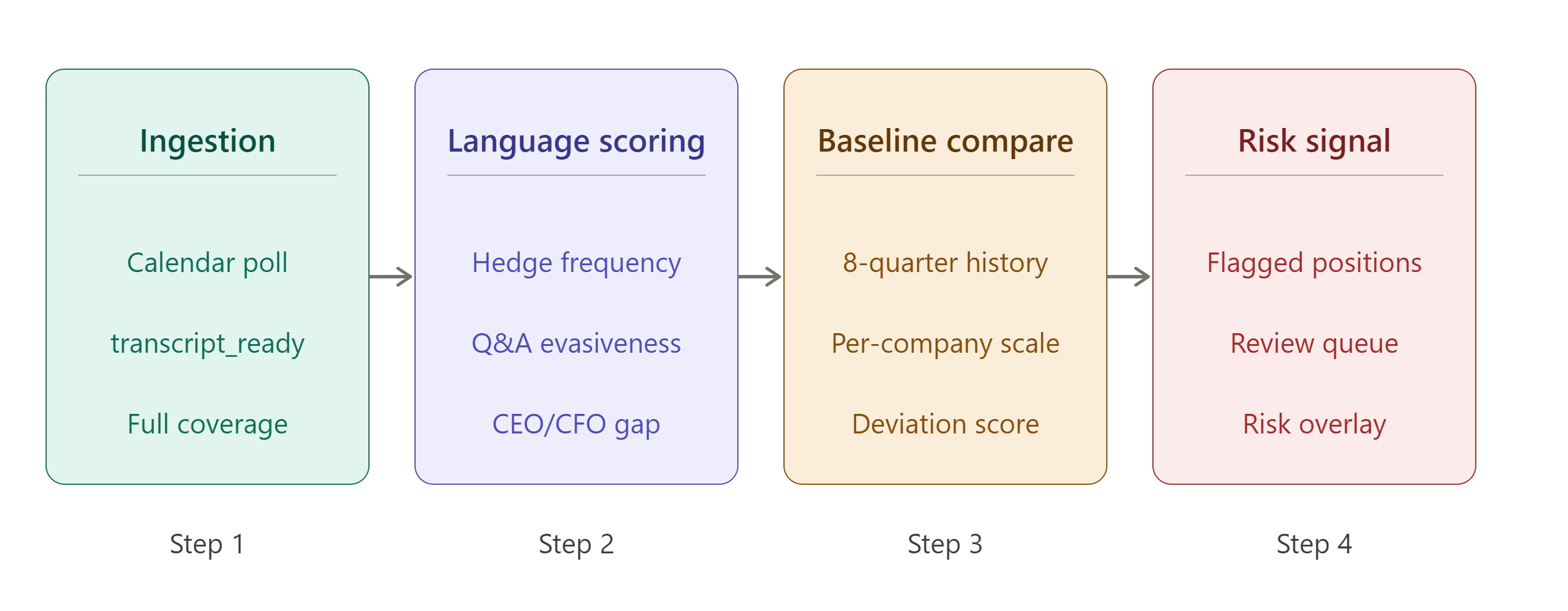
A transcript-based risk pipeline runs in four stages. The first stage is ingestion, pulling transcripts for the full coverage universe each quarter using the calendar endpoint to detect availability through the transcript_ready field. The second stage is language scoring, where each transcript is processed against the four signal categories described above. The third stage is baseline comparison, where each company's current-quarter scores are measured against its own trailing four to eight quarter average rather than against an absolute scale. The fourth stage is risk signal output, where companies showing a meaningful negative deviation from their own baseline are flagged for review.
The baseline comparison step matters more than it might initially appear. A company with a naturally cautious communication style will always score lower in absolute hedge word frequency than a company with a more assertive style. What matters for risk detection is the change relative to that company's own historical pattern, not where it sits on an absolute scale across the full universe.
from earningscall import get_calendar
from datetime import date
calendar = get_calendar(date(2026, 5, 1))
Polling the calendar each morning during earnings season allows the ingestion stage to queue transcripts as soon as transcript_ready turns true, keeping the risk signal current without manual intervention.
Integrating Transcript Signals into Portfolio Risk Models
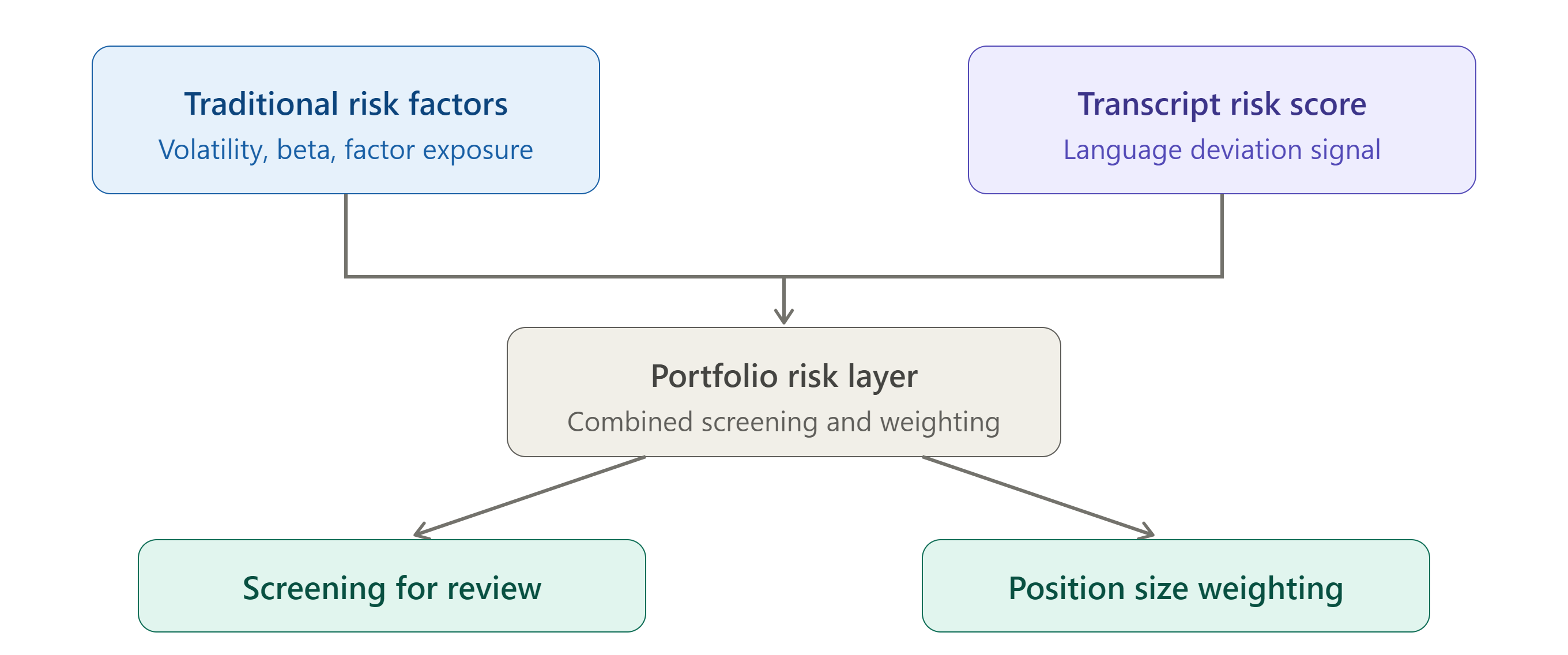
A transcript-derived risk score should not replace existing factor models. It works best as an additional input layered alongside traditional measures such as volatility, beta, and earnings surprise history.
One practical integration approach is treating the transcript risk score as a screening layer. Positions where the score shows a significant negative deviation from baseline are surfaced for deeper qualitative review, even if traditional risk metrics have not yet flagged any concern. This positions the signal as an early warning mechanism rather than a standalone risk model, which keeps it complementary to existing infrastructure rather than competing with it.
Another approach treats the score as a weighting input. Positions with deteriorating language signals can be flagged for reduced position sizing or tighter stop-loss thresholds, even before the numerical thesis changes. This is consistent with findings in the Journal of Finance and related academic literature, where textual signals from corporate communications have been shown to have predictive value for subsequent return volatility, independent of the numerical content disclosed in the same period.
For teams already running sentiment infrastructure on earnings data, How to Build a Hedge Fund Earnings Sentiment Dashboard covers the broader scoring architecture that a risk signal can extend.
Operational Considerations for Production Use
Running a transcript risk pipeline across a full coverage universe each earnings season introduces a few operational requirements worth planning for in advance.
Rate limiting matters during peak reporting weeks, when dozens of companies may report within a 48-hour window. Using the SDK's built-in retry configuration with exponential backoff prevents queue failures when transcript volume spikes.
Historical baseline storage is essential, since the entire signal depends on comparing current-quarter language against a company's own trailing history. A rolling eight-quarter window, stored alongside each company's transcript scores, provides enough history for a stable baseline without overweighting outdated communication patterns from years prior.
Combining the transcript-based risk signal with an automated alert layer can shorten the gap between signal generation and analyst review. Build an Earnings Call Alert System with EarningsCall API and Claude shows how to route flagged transcripts directly to a notification channel the moment a deviation is detected.
FAQ
What is earnings transcript risk analysis?
Earnings transcript risk analysis is the practice of measuring linguistic signals in earnings call transcripts, such as hedging language, guidance consistency, and management tone divergence, to identify early indicators of company-specific risk that have not yet appeared in numerical financial data.
How is quant earnings data different from traditional financial data?
Quant earnings data refers to structured, programmatically accessible transcript content from earnings calls, including prepared remarks and Q&A sections, that can be processed systematically across a large company universe. Traditional financial data covers numerical metrics like revenue and EPS, while transcript data captures the qualitative language used to discuss those metrics.
Can earnings call language really predict risk before it shows up in price data?
Academic research on textual analysis of corporate disclosures has found that language signals in earnings communications can carry information not yet reflected in stock prices or analyst estimates. This does not mean transcript signals are predictive in isolation, but they can serve as a useful complement to traditional quantitative risk indicators.
What companies does the EarningsCall API cover for transcript data?
EarningsCall provides transcript access for 9,000+ public companies through a Python SDK and JavaScript SDK, with multiple access levels including separated prepared remarks and Q&A sections.
Should a transcript risk score replace traditional risk models?
No. A transcript-derived risk score works best as a complementary signal layered alongside existing quantitative risk measures such as volatility and factor exposure, rather than as a standalone replacement for established risk frameworks.
Conclusion
Earnings transcript risk analysis gives quant teams a way to surface risk signals that traditional numerical models structurally cannot see until after the fact. Building this capability on quant earnings data from the EarningsCall API means starting with clean, structured transcript ingestion, scoring language signals against a company's own historical baseline rather than an absolute scale, and integrating the resulting score as a complementary layer within an existing risk framework.
The technical foundation, transcript access, section separation, and calendar-based polling, is the same infrastructure used across sentiment dashboards and alert systems built on the EarningsCall API. For quant teams looking to extend their risk coverage beyond price-based signals, transcript language is one of the more underused data sources still available at scale.
For full API documentation and SDK integration guides, visit the EarningsCall developer guide. For company filings and supplemental financial data, SEC EDGAR is the primary public resource.